Frontier AI Models Outperform Clinical Tools in Medical Queries
Independent evaluation of real physician questions reveals general-purpose LLMs like GPT-5.2 and Gemini exceed specialized medical AI systems.
Frontier AI Models Outperform Clinical Tools in Medical Queries
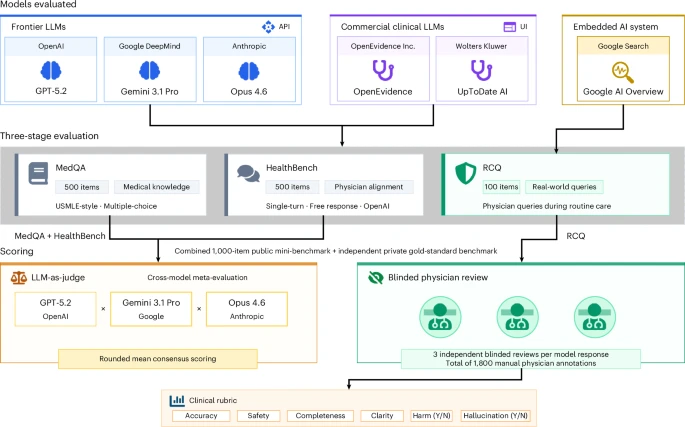
General-purpose large language models consistently outperformed specialized clinical AI tools across multiple evaluations, including real physician queries from active clinical settings, according to a new independent study.
Researchers compared three frontier LLMs—OpenAI's GPT-5.2, Google's Gemini 3.1 Pro, and Anthropic's Claude Opus 4.6—against two clinical AI tools built specifically for healthcare: OpenEvidence and UpToDate Expert AI. The evaluation spanned medical licensing exam questions, alignment with expert clinicians, and 100 actual queries from physicians using AI during patient care.
Real-World Clinical Performance
The most revealing test involved queries physicians submitted to an AI system at NYU Langone Health during live clinical use. Twelve U.S. clinicians performed blinded reviews of how each model answered these questions, rating responses on clinical correctness, completeness, safety, and clarity.
Frontier models formed a clear top tier. Gemini scored 3.62 out of 4, GPT-5.2 scored 3.54, and Claude scored 3.52, with no significant differences among them. The clinical tools lagged behind: OpenEvidence scored 3.24 and UpToDate Expert AI scored 3.17. Notably, Google's AI Overview—the auto-enabled search feature many physicians encounter routinely—matched the clinical tools' performance.
On medical licensing exam questions, Gemini achieved 97.4% accuracy compared to 89.6% for OpenEvidence and 88.4% for UpToDate. The pattern held across a separate benchmark measuring alignment with expert clinical judgment, where GPT-5.2 scored 88.0 compared to roughly 62 for both clinical tools.
Why it matters
Healthcare organizations are rapidly adopting specialized clinical AI tools based on claims of superior medical performance, often without independent verification. This study demonstrates that general-purpose models may deliver better clinical utility than domain-specific systems, with significant implications for hospital procurement decisions, regulatory oversight, and patient safety. The finding that widely available tools like Google AI Overview perform comparably to subscription clinical systems raises questions about the value proposition of specialized medical AI products.
Architecture Questions
The clinical tools' architectures remain proprietary, making it difficult to pinpoint why they underperformed. The researchers note that retrieval-augmented generation—likely used by both OpenEvidence and UpToDate Expert AI—can actually harm performance when irrelevant material is retrieved or poorly integrated. Frontier models may benefit from larger training datasets, faster development cycles, and more extensive alignment work.
The study acknowledges important limitations. Clinical tools lack public APIs, requiring manual browser queries that limited sample size. Industry-created benchmarks may favor their creators' systems. The evaluation didn't assess response speed or citation quality, both relevant for clinical workflow.
UpToDate AI refused to answer 19% of queries, significantly more than other models. Safety outcomes—harmful content and hallucinations—showed no significant differences across any models tested.
The findings suggest that scale, alignment, and cross-domain reasoning may matter more than medical specialization for many clinical tasks. However, the researchers caution this represents a snapshot of rapidly evolving technology, and deeply specialized medical tasks might still benefit from domain-specific approaches.
The study was published in Nature Medicine and conducted by researchers at NYU Langone Health, who first reported these findings.
This is an original analysis by the Omega editorial team. Source reporting: AI Watch.
Want systems like this working for your business?
Book a Call