P-EAGLE Parallelizes Speculative Decoding for LLM Inference
AWS's open-source method eliminates sequential bottlenecks in draft token generation, delivering up to 1.69x throughput gains over EAGLE-3.
P-EAGLE Parallelizes Speculative Decoding for LLM Inference
AWS has developed and open-sourced P-EAGLE (Parallel-EAGLE), a breakthrough approach to speculative decoding that eliminates the sequential bottleneck plaguing existing methods. The technique is now natively supported in Amazon SageMaker JumpStart, enabling one-click deployment of accelerated inference endpoints.
Speculative decoding uses a lightweight draft model to predict multiple future tokens, which a larger target model then verifies in a single forward pass. While methods like EAGLE-3 have shown promise, they generate draft tokens autoregressively—each candidate depends on the previous one, requiring K sequential forward passes to produce K draft tokens. This linear relationship between speculation depth and latency creates a ceiling on performance gains.
P-EAGLE transforms this sequential process into a fully parallel operation by predicting all draft tokens simultaneously in one forward pass. When a target model generates the token "Paris," traditional EAGLE needs four sequential passes to propose ", known for its." P-EAGLE generates all four tokens at once by filling future positions with learnable placeholders.
Why it matters
As enterprises deploy increasingly large language models for production workloads—where median output lengths reach 3,900 tokens and P90 outputs exceed 10,800 tokens—inference throughput directly impacts cost and user experience. P-EAGLE's parallel architecture allows deeper speculation without proportional latency penalties, a critical advantage for long-form generation tasks like code synthesis and technical documentation. The method maintains mathematical equivalence to standard autoregressive output, meaning acceleration comes with zero quality compromise.
Breaking the sequential dependency
P-EAGLE achieves parallelization through two learnable parameters that replace missing inputs at future draft positions. A mask token embedding substitutes for unknown previous-token embeddings at positions 2 through K, while a shared hidden state vector replaces position-specific hidden states that would normally require prior forward passes to compute.
With these placeholders, all K draft positions can be constructed simultaneously. Position 1 uses the actual token embedding and captured hidden states from the target model's most recent generation. Positions 2 through K use the learned placeholders, breaking the dependency chain. All positions pass through the drafter's transformer layers—just four layers comprising 2-5% of target model parameters—in a single forward pass.
Benchmark performance
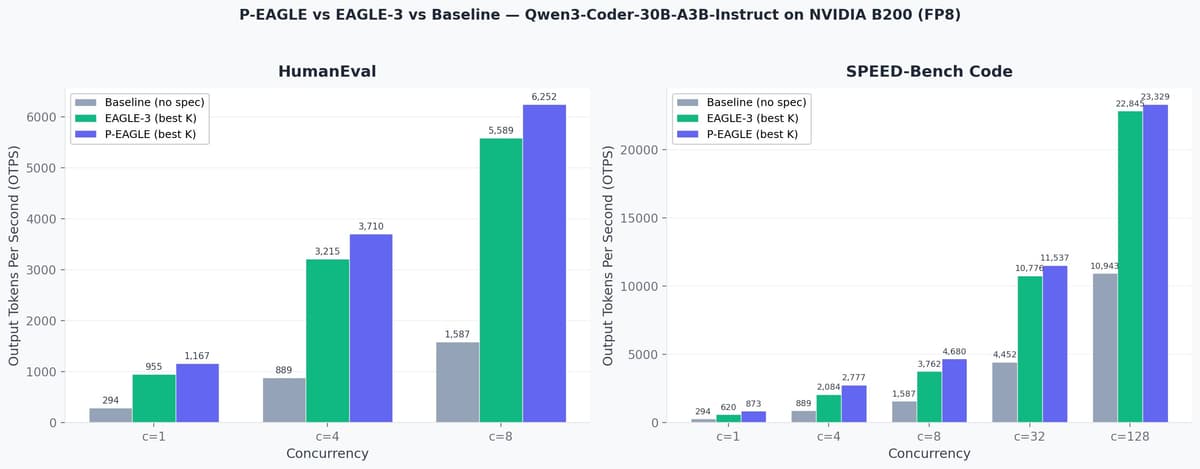
AWS tested P-EAGLE against EAGLE-3 and baseline inference on Qwen3-Coder-30B-A3B-Instruct running on NVIDIA B200 GPUs with FP8 quantization. On HumanEval at concurrency level 8, P-EAGLE with K=11 achieved 6,252 output tokens per second compared to EAGLE-3's 5,589, a 1.12x improvement. On SPEED-Bench Code at concurrency level 1, P-EAGLE delivered 1.41x speedup over EAGLE-3.
The performance advantage stems from P-EAGLE's ability to increase speculation depth without scaling latency. While EAGLE-3 peaks at K=3 before overhead erodes gains, P-EAGLE achieves optimal throughput at K=7 or K=11 because all draft tokens cost the same: one forward pass.
Deployment on SageMaker JumpStart
Amazon SageMaker JumpStart now supports P-EAGLE for four foundation models at launch: GPT-OSS-120B, GPT-OSS-20B, Qwen3-Coder-30B-A3B-Instruct, and Gemma-4-31B-IT. Each model includes pre-trained P-EAGLE drafter heads, eliminating the need for manual training or custom container configuration.
Deployment requires selecting a compatible model from the JumpStart hub, where P-EAGLE is pre-configured via the SM_VLLM_SPECULATIVE_CONFIG environment variable. Setting "parallel_drafting": true activates the P-EAGLE pipeline, with num_speculative_tokens controlling draft depth. Endpoints provision in minutes and serve production traffic immediately.
These details were first reported by AWS in a technical blog post on the Amazon Web Services Machine Learning Blog.
Technical foundation
P-EAGLE's training framework uses a sequence partition algorithm supporting sequences up to 20,000 tokens, matching the context lengths encountered at inference time. Methods trained on shorter sequences experience up to 25% acceptance rate degradation on long-context workloads. The drafter captures hidden states from multiple layers of the target model—layers 2, L/2, and L-1, concatenated to 3d dimensions—to encode contextual understanding at each generation step.
Because speculative decoding verifies all draft tokens against the target model, final output remains mathematically identical to standard autoregressive generation. P-EAGLE accelerates throughput without altering model behavior or compromising quality.
This is an original analysis by the Omega editorial team. Source reporting: AI Watch.
Want systems like this working for your business?
Book a Call

