AWS Launches Automated Pipeline for Converting Paper Medical Records to FHIR
New serverless architecture combines Bedrock Data Automation and HealthLake to extract structured clinical data from scanned PDFs without custom ML models.
AWS demonstrates end-to-end medical record digitization
AWS has published a technical blueprint for automating the conversion of paper medical records into standardized electronic health data, addressing a persistent challenge for healthcare organizations managing millions of disconnected paper documents.
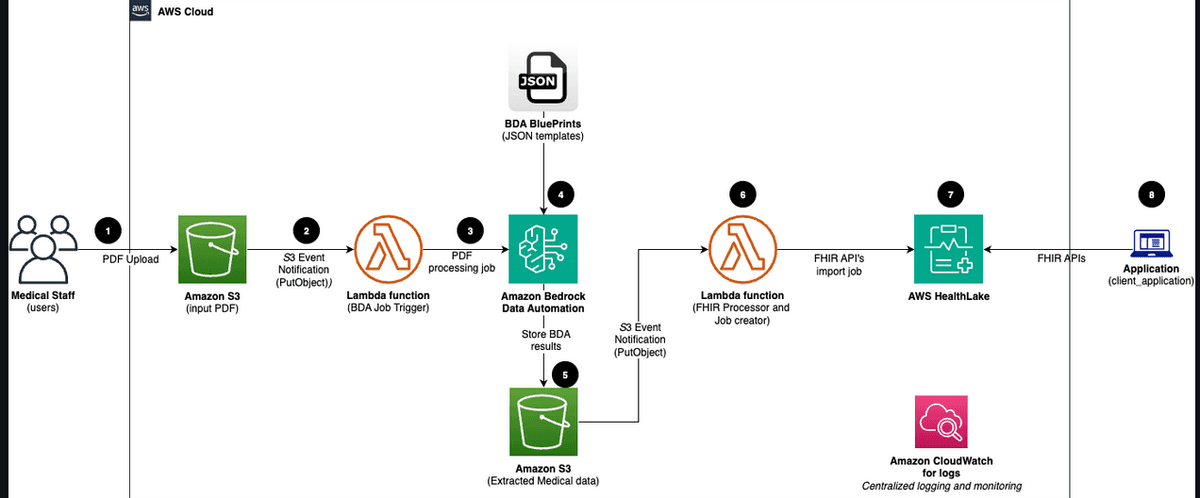
The solution, detailed in an AWS Architecture Blog post, combines Amazon Bedrock Data Automation with AWS HealthLake to create an event-driven pipeline that transforms scanned PDF medical records into FHIR R4-compliant data without requiring custom machine learning models or manual template configuration.
According to AWS, the architecture extracts more than 50 structured clinical fields from scanned documents, including patient demographics, diagnoses with ICD-10 codes, medications, vital signs, and laboratory results. The entire infrastructure deploys via CloudFormation in approximately 15 to 20 minutes.
Why it matters
Paper medical records create tangible care gaps. When patients arrive at new facilities, clinicians often proceed with incomplete information because retrieving and interpreting historical records is too time-consuming. Manual digitization remains expensive, error-prone, and fundamentally unscalable. This architecture demonstrates how healthcare organizations can bridge legacy paper systems and modern interoperable data standards using managed AI services rather than building custom extraction models for every form type.
How the pipeline works
The solution operates in three phases. First, CloudFormation provisions all required resources including S3 buckets, Lambda functions, IAM roles, KMS keys, and a HealthLake FHIR R4 datastore.
The processing phase is fully event-driven. When a PDF uploads to the S3 input bucket, an event triggers the first Lambda function, which calls Bedrock Data Automation. BDA applies a custom medical blueprint to extract clinical fields, each returned with a confidence score between 0.0 and 1.0. BDA writes its JSON output to an S3 output bucket, which triggers the second Lambda function. This FHIR Processor maps extracted fields to appropriate FHIR R4 resource types, assembles a FHIR Bundle, exports it as NDJSON, and triggers a HealthLake import job.
Once data lands in HealthLake, it becomes immediately queryable through standard FHIR R4 API endpoints. Python scripts included in the reference implementation authenticate using AWS Signature Version 4 and support searches by patient, condition, medication, or lab result type.
Production considerations
AWS emphasizes this is a demonstration sample designed for synthetic data only. The architecture includes IAM roles with least-privilege permissions, S3 bucket access controls, KMS encryption for HealthLake data at rest, and CloudWatch logging. However, organizations processing real Protected Health Information must implement additional controls including a Business Associate Addendum, VPC isolation with PrivateLink, comprehensive audit logging, MFA, and HIPAA compliance monitoring through Security Hub.
The solution currently supports US East (N. Virginia) and US West (Oregon) regions where Bedrock Data Automation is available. AWS estimates testing with approximately 100 medical records per month costs between $50 and $100, with production workloads processing 10,000 records monthly running $2,000 to $3,000. Primary cost drivers are Bedrock Data Automation page processing fees and HealthLake search requests.
The architecture was first detailed by AWS in a post on the AWS Architecture Blog, which includes a GitHub repository with deployment scripts, sample medical records, and query utilities.
This is an original analysis by the Omega editorial team. Source reporting: Automation Watch.
Want systems like this working for your business?
Book a Call
